Meet Alibaba's EMO: Emote Portrait Alive

In recent years, we are witnessing the advancements that are happening in the field of image and video generation.
One of the recent development in this domain is EMO: Emote Portrait Alive a framework introduced by Alibaba's Group Institute for Intelligent Computing.
EMO utilizes an audio2video difussion model to generate expressive portrait videos with remarkable realism and accuracy.EMO pushes the boundaries of What is possible in talking head video generation.
Understanding the EMO Framework
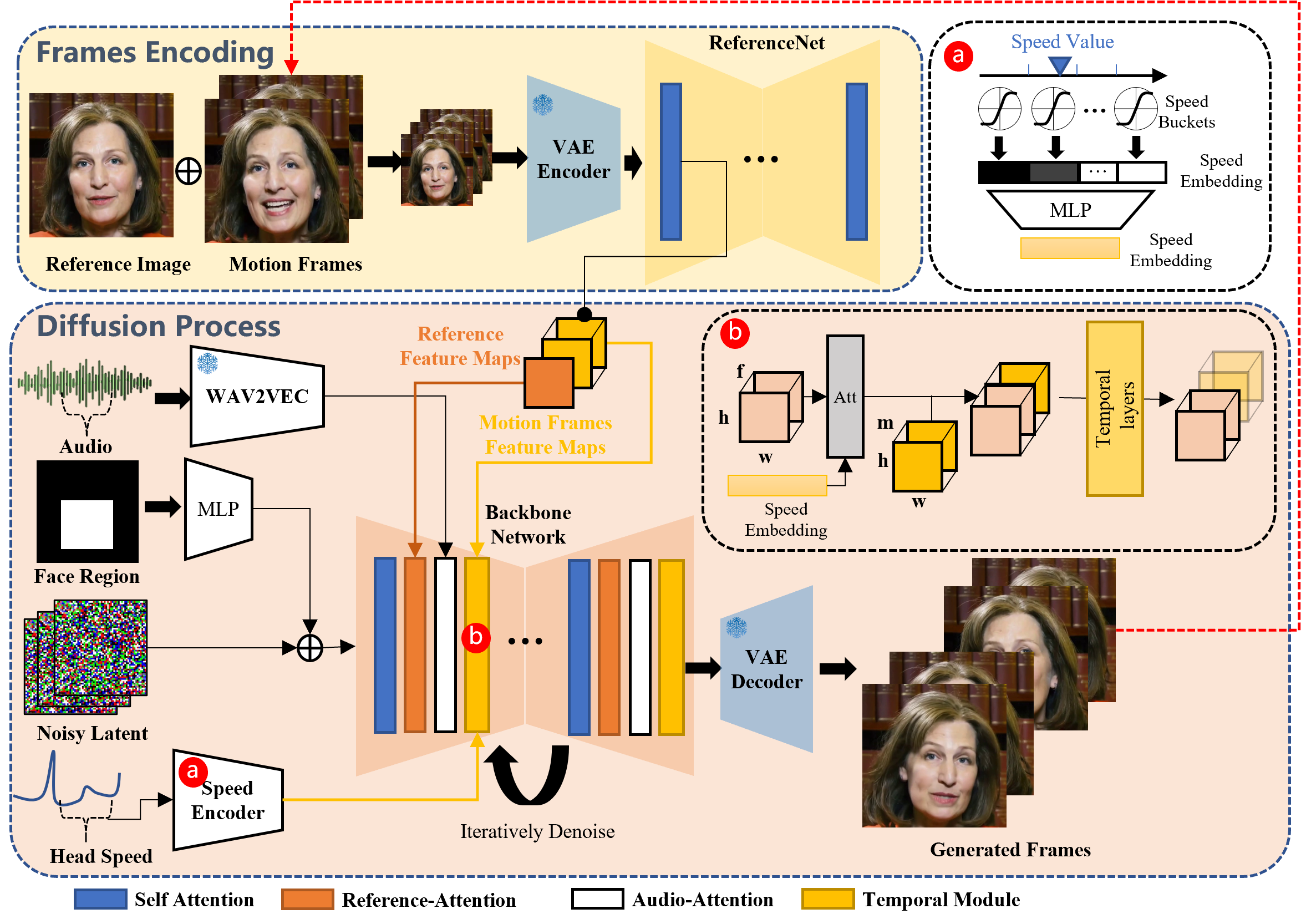
The EMO Framework is a two stage process that combines audio and visual information to generate highly expressive portrait videos.
In the Initial stage called Frames encoding, a neural network called ReferenceNet which extracts features from a single reference image and motion frames. This encoding process lays the foundation for the subsequent difussion process.
During the Diffusion Process stage, EMO utilizes a pretrained audio encoder to process the audio embedding. The facial region mask is integrated with multi-frame noise, which governs the generation of facial imagery.
The Backbone Network, incorporating Reference-Attention and Audio-Attention mechanisms, plays a crucial role in preserving the character’s identity and modulating their movements.
Additionally, Temporal Modules are employed to manipulate the temporal dimension and adjust the velocity of motion.
The combination of these innovative techniques enables EMO to generate vocal avatar videos with expressive facial expressions, various head poses, and any duration depending on the length of the input audio.
Vocal Avatar Generations
EMO goes beyond traditional talking head videos by introducing the concept of vocal avatar generation.
By inputting a single character image and a vocal audio, such as singing. EMO can generate vocal avatar videos with expressive facial expressions, various head poses, and any duration based on the length of the input audio.
Singing Avatars
EMO can generate singing avatars that convincingly mimic the facial expressions and head movements of the reference character.
Multilingual and Multicultural Expressions
EMO supports songs in various languages and brings diverse portrait styles to life. It intuitively recognizes tonal variations in the audio, enabling the generation of dynamic, expression-rich avatars.
EMO framework is its ability to support songs in various languages and bring diverse portrait styles to life.
With its intuitive recognition of tonal variations in audio, EMO can generate dynamic and expression-rich avatars that reflect the cultural nuances of different languages.
Talking with different characters
EMO framework can accommodate spoken audio in various languages and animate portraits from bygone eras, paintings, 3D models, and AI-generated content.
By infusing these characters with lifelike motion and realism, EMO expands the possibilities of character portrayal in multilingual and multicultural contexts.
Training and Dataset
The EMO model was trained with a dataset of over 250 hours of footage, and more than 150 million images.
This dataset includes the footages from television interviews, singing performanaces, covering multiple languages.
Qualitative Comparison
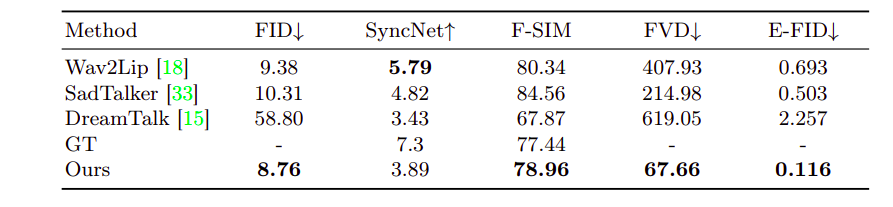
In the figure, you can find the visual comparison between the EMO method and previous approaches. When given a single reference image, Wav2Lip often produces videos with blurry mouth regions and static head poses, lacking eye movement.
DreamTalk’s supplied style clips may distort original faces, limiting facial expressions and head movement dynamism. In contrast, the EMO method outperforms SadTalker and DreamTalk by generating a broader range of head movements and dynamic facial expressions. The EMO approach doesn’t utilize audio-driven character motion without relying on direct signals like blend shapes

Limitations
EMO demonstrates amazing capabilities in generating expressive portrait videos, there are still limitations to be addressed.
The framework relies heavily on the quality of the input audio and reference image, and improvements in audio-visual synchronization can further enhance the realism of the generated videos.
Code
When we tried to access the Git repo of EMO we can see that there is no code available in the repo and a lot of issues has been created for the same. may be it would have been taken down.
And it is mentioned that this project is inteded solely for academic research and effect demonstration.
Reference Link: https://humanaigc.github.io/emote-portrait-alive/
Github Link: https://github.com/HumanAIGC/EMO




