Firestore Vector Search

On Google I/O - 24, Firebase team has introduced Search with Vector embeddings using Firestore.
What is RAG?
You will be get better results from LLM when you put more information in it. such as writing some long prompts and get the better result for it. Ideally no one would have the time to write those long prompts There's now a standardized approach to add more information to a question that user asks and it is called Retrieval-Augumented-Generation (RAG).
Let's see how RAG works say for example you have a lot of information about one specific domain like your product documentation. To implement RAG first we will split the documentation that is one file for each topic in the documentation. Now for each topic you will generate a vector embedding.
You download a machine learning model from the internet and you pass in the topic text and then you will get a vector representation of that text. In such a way if two topics are closely related then the vectors are also close to each other.
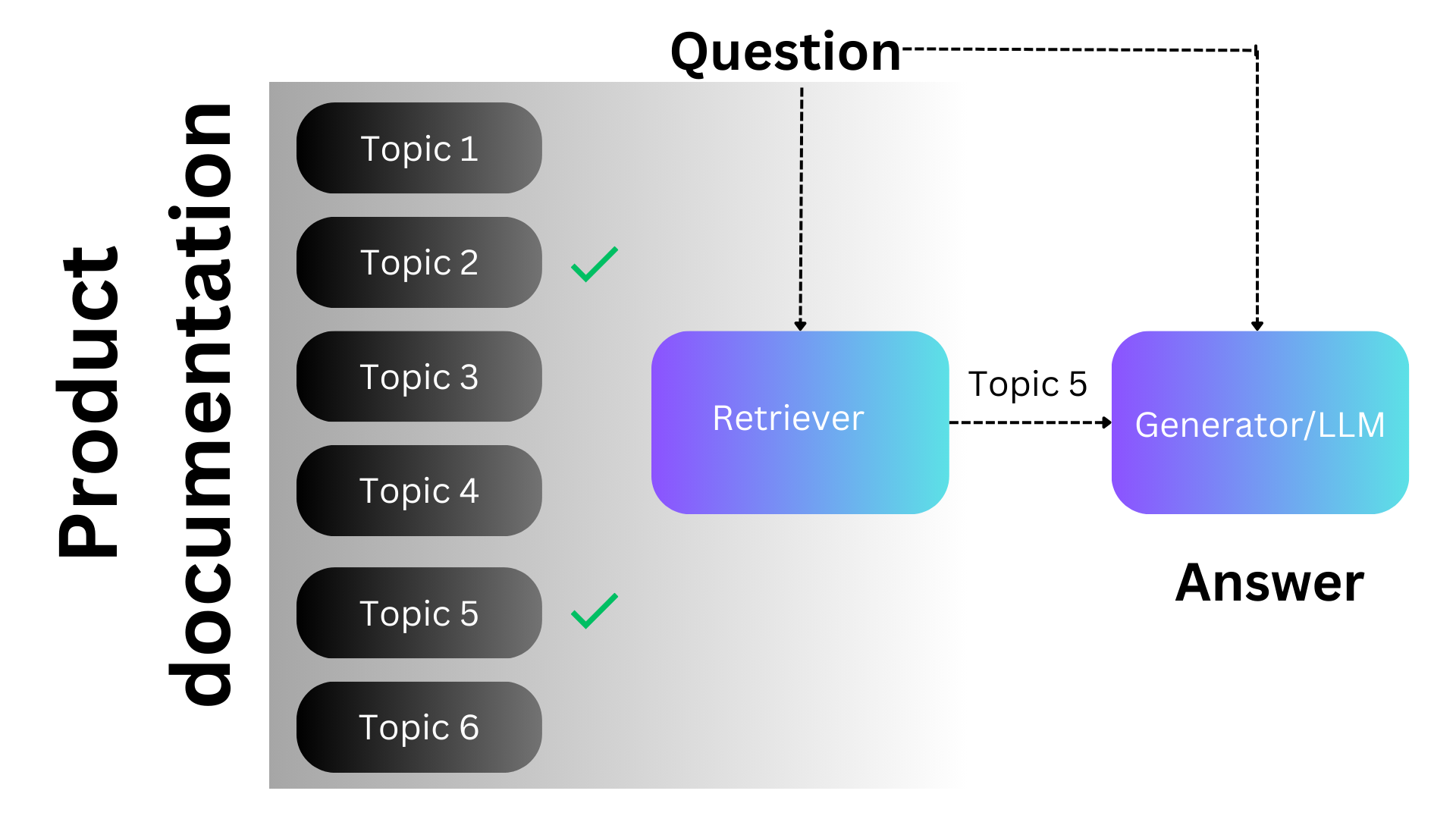
So now we have the topic files and the vector embeddings for each of those topics. Now when the user asks the questions we find the topics that are closely related to that question so we run the same question in the embedding model and compare the vectors.
Then we will pass those topics and questions to LLM which will result in a better answer.
How do we find the near vector values

Here we have a data about food and for each food it is categorized into 3 that is sweetness, crunchiness and spiciness. Now, if i say i like the sweetness of apple which will categorizes the sweetness section and would take apple and ice-cream. But if i say i like apples and it can't move on to next category itself.
In this case we have done a similarity search based on the prompt sweetness based on the vector values (our case apples) and the nearest neighbour values that based on sweetness. This is how RAG works
For example purpose we have 3 columns but in real time use cases we can see 100's and 1000's columns and values.
Firestore Vector Search
Now you can store vector values in Firestore documents and you can search for nearby vector values in your Firestore. You can store the topics in Firestore documents and for each of the topics you can calculate the embedding vector, you store in that document too.
When the user types the query you calculate the embedding vector for that and display the results either to the user or pass it to LLM.
Example code of how to store a vector embedding document in Firestore
import {
Firestore,
FieldValue,
} from "@google-cloud/firestore";
const db = new Firestore();
const coll = db.collection('indian-coffee-house');
await coll.add({
name: "Indian coffee house",
description: "Information about the Indian coffee house",
embedding_field: FieldValue.vector([1.0 , 2.0, 3.0])
});
and the same can be done in python as well.
Limitations
As you work with vector embeddings, note the following limitations:
The max supported embedding dimension is 2048. To store larger indexes, use dimensionality reduction.
The max number of documents to return from a nearest-neighbor query is 1000.
Vector search does not support real-time snapshot listeners.
You cannot use inequality filters to pre-filter data.
Only the Python and Node.js client libraries support vector search.
Check more about Firestore Vector Search - https://firebase.google.com/docs/firestore/vector-search#node.js
That's an quick update about Firestore Vector Search will catch up in a new post till then Happy Learning !!!




